It’s been long enough that I should go over what TIS-100 _IS_. TIS-100 is a programming puzzle game by the makers of SpaceChem (a previous obsession). Where SpaceChem kind of hid the programming knowledge necessary to solve the puzzles beneath a fun graphical abstraction, TIS-100 just strips away the candy coating. TIS-100 simulates a fictional multicore reduced instruction set computer (RISC). There is no RAM. Sometimes there is a stack or two. Each processor has just one directly-accessible register.
This is SUCH a niche game. Take your set of gamers. From that, select the ones that are programmers or who are interested in programming. From that, select the ones that have experience with assembly language, or are interested in programming at the chip level. From that, select the ones that love optimizing machine code. For a computer that doesn’t exist.
There is a very thin plot to TIS-100, exposed a fragment at a time in notes left by your crazy uncle, the uncle who left you this mystery computer after his tragic death. I’m just two segments from the end….
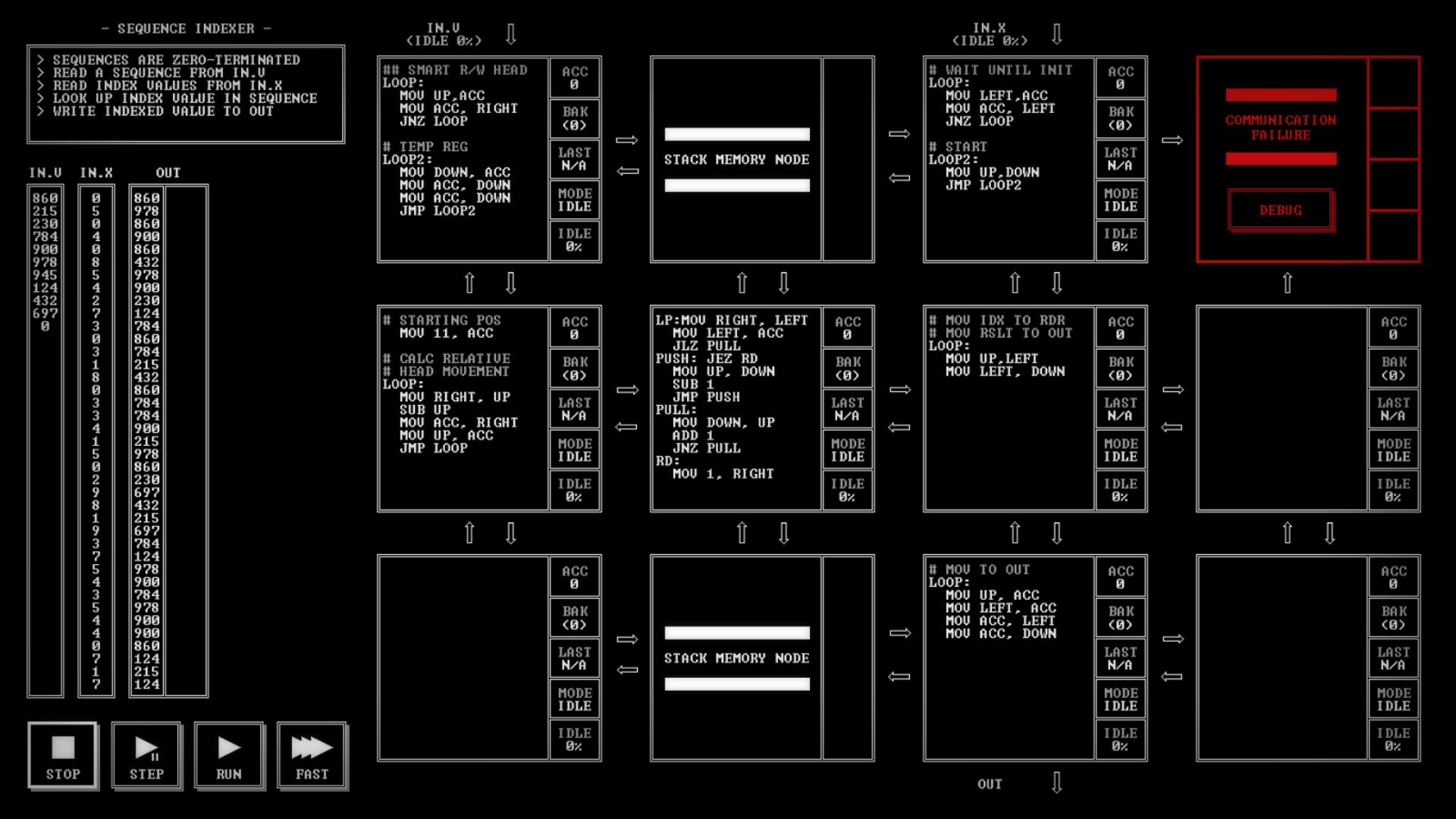
Segment 62711 – Sequence Indexer
- Sequences are zero terminated
- Read a sequence from IN.0
- Read index values from IN.X
- Look up index values in sequence
- Write indexed value to OUT
The processor diagram for this puzzle has two stack nodes with a processor node between them that provide a clue to the solution. The data will be read into the top stack, then we will build a node that moves data from one stack to the other until the correct value is on top of the bottom stack. Then the output node will read this value and… output it.
The first time I tried this puzzle, several months ago, I got stuck trying to limit the amount of data being moved from one stack to the other and I just got overwhelmed. This time, I got a basic solution running and then added the smarter stack management (that’s the node on the middle left).
I got as far as I could, fighting sleep. The automated analysis showed my solution was faster than most, but not fastest by a long shot. I found a much faster solution on the Internet. This better solution was roughly similar, but it included a fast path for when the index was the same as the previous index. It also moved the calculation of the necessary stack motion to the index input node. Mine is way over to the other side, and precious cycles are wasted getting it there. This other solution is the first place I have seen the Jump Relative Offset (JRO) instruction used.
Well, I bow to the better programmer, but I am happy with my solution 🙂
Next: A Sequence Sorter!
